언어 (Language)
지금까지 과정에서 우리는 AI가 처리할 수 있도록 작업과 데이터를 형성해야 했다. 오늘은 인간의 언어를 처리하기 위해 AI를 어떻게 구성할 수 있는지 살펴볼 것이다.
자연어 처리(Natural Language Processing)는 AI가 인간의 언어를 입력으로 받는 모든 작업에 적용된다. 다음은 이러한 작업의 몇 가지 예이다:
- 자동 요약(automatic summarization): AI가 텍스트를 입력으로 받고 텍스트 요약을 출력으로 생성한다.
- 정보 추출(information extraction): AI에게 텍스트 모음이 제공되고 AI가 데이터를 출력으로 추출한다.
- 언어 식별(language identification): AI에 텍스트가 제공되면 텍스트의 언어를 출력으로 반환한다.
- 기계 번역(machine translation): AI에 원문 언어로 된 텍스트를 입력하면 AI가 대상 언어로 번역 결과를 출력하는 번역이다.
- 명명된 엔터티 인식(named entity recognition): AI에 텍스트가 제공되고 텍스트에 있는 엔터티의 이름(예: 회사 이름)을 추출한다.
- 음성 인식(speech recognition): AI에 음성이 주어지고 텍스트에서 동일한 단어를 생성한다.
- 텍스트 분류(text classification): AI에 텍스트가 주어지고 이를 어떤 유형의 텍스트로 분류해야 하는 경우이다.
- 단어 의미의 모호성 해소(word sense disambiguation): AI가 여러 의미를 가진 단어의 올바른 의미를 선택해야 하는 경우이다(예: 은행은 나무 종류의 은행과 돈을 관리하는 기관의 은행 중 맞는 것을 선택해야 한다.).
구문 분석과 의미 분석(Syntax and Semantics)
구문(Syntax)은 문장 구조이다. 일부 인간 언어의 모국어 화자로서 우리는 문법적 문장을 만들고 비문법적 문장을 틀렸다고 표시하는 데 어려움을 겪지 않는다. 예를 들어, 문장 "Just before nine o'clock Sherlock Holmes steps briskly into the room"은 문법적이지만, 문장 "Just before Sherlock Holmes nine o'clock steps briskly the room"은 문법적이지 않다. 구문은 "I saw the man with the telescope"처럼 동시에 문법적일 수 있고 모호할 수 있다. 망원경을 통해 보면서 (망원경을 든 남자)를 보았는가, 아니면 (남자)를 보았는가? 인간의 말을 구문 분석하고 만들어내려면 AI가 구문을 지정해야 한다.
의미(Semantics)는 단어나 문장의 의미이다. "9시 직전에 셜록 홈스가 활발하게 방에 들어왔다"라는 문장은 "9시 직전에 셜록 홈스가 활기차게 방에 들어왔다"와 구문적으로 다르지만 내용은 사실상 동일하다. 마찬가지로, “9시 몇 분 전, 셜록 홈스가 방으로 빠르게 걸어 들어갔다”라는 문장은 이전 문장과 다른 단어를 사용하지만 여전히 매우 유사한 의미를 전달한다. 문장은 "무색 녹색 아이디어는 격렬하게 잠들어 있다."라는 촘스키의 예에서처럼 완벽하게 문법적일 수도 있지만 완전히 무의미할 수도 있다. 인간의 음성을 구문 분석하고 생성하려면 AI가 의미를 지정해야 한다.
문맥 자유 문법(CFG: Context-Free grammar)
형식 문법(Formal grammar)은 언어에서 문장을 생성하기 위한 규칙 체계이다. 문맥 자유 문법(Context-Free Grammar)에서는 텍스트의 의미를 추상화하여 형식문법을 사용하여 문장의 구조를 표현한다. 다음 예문을 고려해 보자:
- She saw the city.
이것은 간단한 문법 문장이며, 그 구조를 나타내는 구문 트리를 생성하고 싶다. 우리는 각 단어에 품사를 할당하는 것으로 시작한다. She와 city는 명사이고, N으로 표시한다. Saw는 동사이고, V로 표시한다. The는 한정사이고, 다음 명사를 한정되지 않은 것으로 표시하고, D로 표시한다. 이제 위의 문장을 다음과 같이 다시 쓸 수 있다:
- N V D N
지금까지 우리는 각 단어를 의미적 의미에서 품사로 추상화했다. 그러나 문장 속 단어는 서로 연결되어 있으며, 문장을 이해하려면 단어들이 어떻게 연결되는지 이해해야 한다. 명사구(NP)는 명사에 연결되는 단어 그룹이다. 예를 들어, 이 문장에서 she라는 단어는 명사구이다. 또한 the city라는 단어도 한정사와 명사로 구성된 명사구를 형성한다. 동사구(VP)는 동사에 연결되는 단어 그룹이다. saw라는 단어는 그 자체로 동사구이다. 그러나 saw the city라는 단어도 동사구를 구성한다. 이 경우 동사와 명사구로 구성된 동사구이며, 명사구는 다시 한정사와 명사로 구성된다. 마지막으로 전체 문장(S)은 다음과 같이 표현할 수 있다:

AI는 형식문법을 사용해 문장의 구조를 표현할 수 있다. 우리가 설명한 문법에는 위의 간단한 문장을 표현하는 데 충분한 규칙이 있다. 더 복잡한 문장을 표현하려면 형식 문법에 더 많은 규칙을 추가해야 한다.
자연어 도구(nltk)
파이썬에서 흔히 그렇듯이, 위의 아이디어를 구현하기 위해 여러 라이브러리가 작성되었다. nltk(자연어 도구)는 그러한 라이브러리 중 하나이다. 위의 문장을 분석하기 위해, 우리는 문법에 대한 규칙을 알고리즘에 제공할 것이다:
import nltk
grammar = nltk.CFG.fromstring("""
S -> NP VP
NP -> D N | N
VP -> V | V NP
D -> "the" | "a"
N -> "she" | "city" | "car"
V -> "saw" | "walked"
""")
parser = nltk.ChartParser(grammar)
위에서 한 것과 비슷하게, 우리는 다른 것에 포함될 수 있는 가능한 구성 요소를 정의한다. 문장에는 명사구와 동사구가 포함될 수 있고, 구 자체는 다른 구, 명사, 동사 등으로 구성될 수 있으며, 마지막으로 각 품사는 언어의 몇몇 단어에 걸쳐 있다.
sentence = input("Sentence: ").split()
try:
for tree in parser.parse(sentence):
tree.pretty_print()
tree.draw()
except ValueError:
print("No parse tree possible.")
알고리즘에 단어 목록으로 분할된 입력 문장을 제공한 후 함수는 결과 구문 트리(pretty_print)를 인쇄하고 그래픽 표현(draw)도 생성한다.

n -그램(n- grams)
n - gram은 텍스트 샘플에서 n 개 항목의 시퀀스이다. character n -gram에서는 항목이 문자이고, word n -gram에서는 항목이 단어이다. unigram, bigram 및 trigram은 1개, 2개, 3개 항목의 시퀀스이다. 다음 문장에서 처음 세 개의 n - 그램은 "how often have", "often have I", "have I said"이다.
" How often have I said to you that when you have eliminated the impossible whatever remains, however improbable, must be the truth? "
n -gram은 텍스트 처리에 유용하다. AI가 이전에 반드시 전체 문장을 본 것은 아니지만 "have I said"와 같은 문장의 일부를 본 것은 확실하다. 어떤 단어는 다른 단어보다 더 자주 함께 나타나기 때문에 어느 정도 확률로 다음 단어를 예측하는 것도 가능하다. 예를 들어 스마트폰은 사용자가 마지막으로 입력한 몇 단어에서 파생된 확률 분포를 기반으로 단어를 제안한다. 따라서 자연어 처리에 도움이 되는 단계는 문장을 n-gram으로 나누는 것이다.
토큰화(Tokenization)
토큰화는 일련의 문자를 조각(토큰)으로 분할하는 작업이다. 토큰은 단어일 수도 있고 문장일 수도 있으며, 이 경우 작업을 단어 토큰화(word tokenization) 또는 문장 토큰화(sentence tokenization)라고 한다. n -gram을 볼 수 있으려면 토큰화가 필요하다. n-gram은 토큰 시퀀스에 의존하기 때문이다. 공백 문자를 기준으로 텍스트를 단어로 분할하는 것부터 시작한다. 이것은 좋은 시작이지만 "remains"와 같이 구두점이 있는 단어로 끝나기 때문에 이 방법은 불완전하다. 그래서 예를 들어 우리는 구두점을 제거할 수 있다. 그러나 아포스트로피(예: “o'clock”) 및 하이픈(예: “pearl-grey)”이 포함된 단어와 같은 추가 문제에 직면하게 된다. 또한 마침표와 같은 일부 구두점은 문장 구조에 중요하다. 그러나 “Mr.”라는 단어 끝에 마침표와 문장 끝에 마침표를 구별할 수 있어야 한다. 이러한 질문을 다루는 것이 토큰화 과정이다. 결국 토큰이 있으면 n -gram을 살펴볼 수 있다.
마르코프 모델(Markov Models)
전 강의에서 논의했듯이 마르코프 모델은 노드로 구성되며, 각 노드의 값은 유한한 수의 이전 노드에 기반한 확률 분포를 갖는다. 마르코프 모델은 텍스트를 생성하는 데 사용할 수 있다. 이를 위해 텍스트에 대해 모델을 학습한 다음, 앞에 있는 n개 단어를 기반으로 n - 그램의 모든 n - 번째 토큰에 대한 확률을 설정한다. 예를 들어, 트라이그램을 사용하면 마르코프 모델에 두 단어가 있다고 하면 처음 두 단어를 기반으로 확률 분포에서 세 번째 단어를 선택할 수 있다. 그런 다음 두 번째와 세 번째 단어를 기반으로 확률 분포에서 네 번째 단어를 선택할 수 있다. nltk를 사용하여 이러한 모델을 구현한 방법을 보려면 소스 코드의 generator.py를 참조하면 된다. 여기서 모델은 셰익스피어처럼 들리는 문장을 생성하는 방법을 학습한다. 결국 마르코프 모델을 사용하면 종종 문법적이고 인간의 언어 출력과 표면적으로 비슷하게 들리는 텍스트를 생성할 수 있다. 그러나 이러한 문장에는 실제 의미와 목적이 없다.
Bag-of-Words 모델
Bag-of-words는 텍스트를 정렬되지 않은 단어 모음으로 표현하는 모델이다. 이 모델은 구문을 무시하고 문장에 있는 단어의 의미만 고려한다. 이 접근 방식은 감정 분석과 같은 일부 분류 작업에 유용하다(또 다른 분류 작업은 일반 이메일과 스팸 이메일을 구별하는 것이다). 예를 들어 제품 리뷰에서 감정 분석을 사용하여 리뷰를 긍정적 또는 부정적으로 분류할 수 있다. 다음 문장을 고려해 보자:
- “손자가 정말 좋아했어요! 정말 재미있어요!”
- “제품이 며칠 만에 고장 났어요.”
- "제가 오랫동안 플레이한 게임 중 가장 좋은 게임 중 하나입니다."
- “저렴하고 허약해서 그럴 가치가 없어요.”
각 문장의 단어만으로 문법을 무시한다면, 문장 1과 3은 긍정적("loved, " "fun, " "best")이고 문장 2와 4는 부정적("broke, " "cheap, " "flimsy")이라는 것을 알 수 있다.
베이즈 단순화(Naive Bayes)
Naive Bayes는 Bag-of-Words 모델을 사용하여 감정 분석에 사용할 수 있는 기술이다. 감정 분석에서는 "문장에 포함된 단어를 고려하여 문장이 긍정적/부정적일 확률은 얼마입니까?"를 묻는다. 이 질문에 대답하려면 조건부 확률을 계산해야 하며 Bayes의 규칙을 알고 있는 것이 도움이 된다.

이제 이 공식을 사용하여 P(sentiment(감정) | text(텍스트)) 또는 예를 들어 P(positive | "my grandson loved it")를 찾고 싶다. 입력을 토큰화하는 것으로 시작하여 P(positive | "my", "grandson", "loved", "it")이 된다. 베이즈 규칙을 직접 적용하면 다음 식을 얻게 된다. P( "my", "grandson", "loved", "it" | positive ) x P(positive)/P( "my", "grandson", "loved", "it" ). 이 복잡한 식을 사용하면 P(positive | "my", "grandson", "loved", "it")에 대한 정확한 답을 얻을 수 있다.
그러나 P(positive | "my", "grandson", "loved", "it")에 비례하지만 같지 않은 답을 얻고자 한다면 표현식을 단순화할 수 있다. 나중에 확률 분포가 1이 되어야 한다는 것을 안다면 결과 값을 정확한 확률로 정규화할 수 있다. 즉, 위의 표현식을 분자로만 단순화할 수 있다. P("my", "grandson", "loved", "it" | positive)*P(positive). 다시 말하지만, 주어진 b의 조건부 확률이 a와 b의 결합 확률에 비례한다는 지식에 따라 이 표현식을 단순화할 수 있다. 따라서 확률에 대한다음 표현식을 얻게 된다. P(positive, "my", "grandson", "loved", "it") x P(positive). 그러나 이 결합 확률을 계산하는 것은 복잡하다. 각 단어의 확률은 앞에 오는 단어의 확률에 따라 조건이 정해지기 때문이다. P(positive) x P(“my” | positive) x P(“grandson” | positive, “my”) x P(loved | positive, “my”, “grandson”) x P(“it” | positive, “my”, “grandson”, “loved”)를 계산해야 한다.
여기서 우리는 niave Bayes 규칙을 사용한다. 각 단어의 확률은 다른 단어와 독립적이라고 가정한다. 이는 사실이 아니지만 이러한 부정확성에도 불구하고 naive Bayes 규칙은 좋은 감정 추정치를 생성한다. 이 가정을 사용하면 다음과 같은 확률을 얻는다. P(positive) x P(“my” | positive) x P(“grandson” | positive) x P(“loved” | positive) x P(“it” | positive), 계산하기 어렵지 않다. P(positive) = 모든 긍정 샘플 수를 전체 샘플 수로 나눈 값이다. P(“loved” | positive)는 “loved”라는 단어를 긍정 샘플 수로 나눈 긍정 샘플 수와 같다. 미소 짓는 이모티콘과 찡그린 이모티콘을 “positive”와 “negative”라는 단어로 대체한 아래 사진을 예를 들겠다:

오른쪽에는 문장이 긍정적이거나 부정적인 경우 문장에서 발생하는 왼쪽의 각 단어의 조건부 확률이 포함된 표가 표시된다. 왼쪽의 작은 표에서 우리는 긍정적이거나 부정적인 문장의 확률을 볼 수 있다. 왼쪽 하단에는 계산 후 결과 확률이 표시된다. 이 시점에서는 서로 비례하지만 확률 측면에서는 많은 것을 알려주지 않는다. 확률을 얻으려면 값을 정규화하여 P(양수) = 0.6837 및 P(음수) = 0.3163에 도달해야 한다. naive Bayes의 장점은 다른 문장보다 한 문장 유형에서 더 자주 나타나는 단어에 민감하다는 것이다. 우리의 경우, “loved”라는 단어는 긍정적인 문장에서 훨씬 더 자주 나타나서 전체 문장이 부정적인 것보다 긍정적일 가능성이 더 높다. nltk 라이브러리와 함께 Naive Bayes를 사용하여 감정 평가 구현을 보려면 sentiment.py를 확인해 보면 된다.
우리가 마주칠 수 있는 한 가지 문제는 일부 단어가 특정 유형의 문장에 전혀 나타나지 않을 수도 있다는 것이다. 샘플의 긍정 문장에 "grandson"라는 단어가 없다고 가정해 보자. 그러면 P(" grandson " | positive) = 0이 되고 문장이 긍정일 확률을 계산하면 0이 된다. 그러나 실제로는 그렇지 않다(손자를 언급하는 모든 문장이 부정인 것은 아니다). 이 문제를 해결하는 한 가지 방법은 가산 평활화(Additive Smoothing)를 사용하는 것이다. 여기서는 분포의 각 값에 α 값을 더하여 데이터를 평활화한다. 이렇게 하면 특정 값이 0이더라도 α를 더하면 긍정 또는 부정 문장의 전체 확률을 0으로 곱하지 않는다. 특정 유형의 가산 평활화인 라플라스 평활화(Laplace Smoothing)는 분포의 각 값에 1을 더하여 모든 값이 최소한 한 번은 관찰되었다고 가정한다.
단어 표현(Word Representation)
우리는 AI에서 단어 의미를 표현하고 싶다. 앞서 살펴본 것처럼 AI에 숫자 형식으로 입력을 제공하는 것이 편리하다. 이를 해결하는 한 가지 방법은 One-Hot Representation을 사용하는 것이다. 여기서 각 단어는 단어 수만큼의 값으로 구성된 벡터로 표현된다. 1과 같은 벡터의 단일 값을 제외하고 다른 모든 값은 0과 같다. 단어를 구별하는 방법은 값 중 어느 것이 1 인지에 따라 단어당 고유한 벡터로 끝난다. 예를 들어, "He wrote a book"이라는 문장은 4개의 벡터로 표현될 수 있다.
- [1, 0, 0, 0] (He)
- [0, 1, 0, 0] (wrote)
- [0, 0, 1, 0] (a)
- [0, 0, 0, 1] (book)
그러나 이 표현은 네 단어가 있는 세상에서는 작동하지만, 사전에서 단어를 표현하려면 50,000개의 단어가 있을 수 있는데, 결국 길이가 50,000인 50,000개의 벡터가 생긴다(;;). 이것은 엄청나게 비효율적이다. 이런 종류의 표현에서 또 다른 문제는 "wrote"와 "authored"와 같은 단어 간의 유사성을 표현할 수 없다는 것이다. 대신, 우리는 의미가 벡터의 여러 값에 분산되는 분산 표현(Distributed Representation)의 개념으로 전환한다. 분산 표현을 사용하면 각 벡터는 제한된 수의 값(50,000개보다 훨씬 적음)을 가지며 다음과 같은 형태를 취한다.
- [-0.34, -0.08, 0.02, -0.18, …] (He)
- [-0.27, 0.40, 0.00, -0.65, …] (wrote)
- [-0.12, -0.25, 0.29, -0.09, …] (a)
- [-0.23, -0.16, -0.05, -0.57, …] (book)
이를 통해 더 작은 벡터를 사용하면서 각 단어에 대해 고유한 값을 생성할 수 있다. 또한 이제 벡터의 값이 얼마나 다른지를 통해 단어 간의 유사성을 나타낼 수 있다.
"You shall know a word by the company it keeps"는 영어학자 JR Firth의 아이디어이다. 이 아이디어를 따르면 인접한 단어로 단어를 정의할 수 있다. 예를 들어, "for ___ he ate"라는 문장을 완성하는 데 사용할 수 있는 단어는 제한적이다. 이러한 단어는 아마도 "breakfast", "lunch", "dinner"와 같은 단어일 것이다. 이를 통해 특정 단어가 나타나는 환경을 고려하면 단어의 의미를 유추할 수 있다는 결론에 도달하게 된다.
단어를 벡터로(word2 vec)
word2 vec는 단어의 분산 표현을 생성하는 알고리즘이다. 이는 Skip-Gram Architecture를 통해 수행된다. 스킵 그램 아키텍처는 타깃 단어가 주어졌을 때 맥락을 예측하는 신경망 아키텍처이다. 이 아키텍처에서 신경망은 모든 타깃 단어에 대한 입력 단위를 갖는다. 더 작은 단일 숨겨진 층(예: 50 또는 100개 단위, 하지만 이 숫자는 유연함)은 단어의 분산 표현을 나타내는 값을 생성한다. 이 숨겨진 층의 모든 단위는 입력층의 모든 단위에 연결된다. 출력층은 타깃 단어와 유사한 맥락에 나타날 가능성이 있는 단어를 생성한다. 신경망 챕터에서 본 것과 유사하게 이 네트워크는 역전파 알고리즘을 사용하여 학습 데이터 세트로 학습해야 한다.
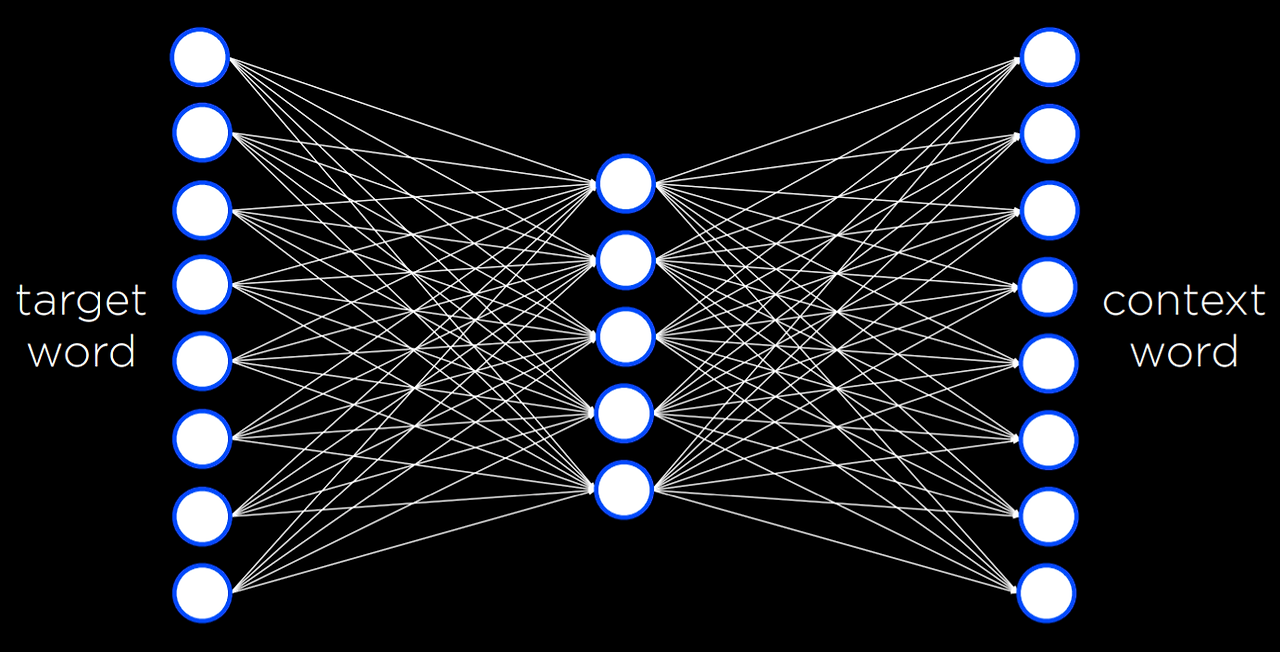
이 신경망은 매우 강력한 것으로 밝혀져 있다. 프로세스가 끝나면 모든 단어는 벡터 또는 숫자 시퀀스로 끝난다.
예를 들어,
book: [-0.226776 -0.155999 -0.048995 -0.569774 0.053220 0.124401 -0.091108 -0.606255 -0.114630 0.473384 0.061061 0.551323 -0.245151 -0. 014248 -0.210003 0.316162 0.340426 0.232053 0.386477 -0.025104 -0.024492 0.342590 0.205586 -0.554390 -0.037832 -0.212766 -0.048781 - 0.088652 0.042722 0.000270 0.356324 0.212374 -0.188433 0.196112 -0.223294 -0.014591 0.067874 -0.448922 -0.290960 -0.036474 -0.148416 0.448422 0.016454 0.071 613 -0.078306 0.035400 0.330418 0.293890 0.202701 0.555509 0.447660 -0.361554 -0.266283 -0.134947 0.105315 0.131263 0.548085 -0.1 95238 0.062958 -0.011117 -0.226676 0.050336 -0.295650 -0.201271 0.014450 0.026845 0.403077 -0.221277 -0.236224 0.213415 -0.163396 -0.218948 -0.242459 -0.346984 0.282615 0.014165 -0.342011 0.370 489 -0.372362 0.102479 0.547047 0.020831 -0.202521 -0.180814 0.035923 -0.296322 -0.062603 0.232734 0.191323 0.251916 0.150993 -0.0 24009 0.129037 -0.033097 0.029713 0.125488 -0.018356 -0.226277 0.437586 0.004913]
이러한 숫자 자체로는 큰 의미가 없다. 그러나 코퍼스(corpus)에서 가장 유사한 벡터를 가진 다른 단어를 찾으면 book이라는 단어와 가장 유사한 단어를 생성하는 함수를 실행할 수 있다. 이 네트워크의 경우 다음과 같다. book, books, essay, memoir, essays, novella, anthology, blurb, autobiography, audiobook. 이것은 컴퓨터에게는 나쁘지 않다! 특정 의미를 갖지 않는 숫자의 집합을 통해 AI는 글자나 소리가 아니라 의미에서 book과 실제로 매우 유사한 단어를 생성할 수 있다.
벡터의 차이에 따라 단어 간의 차이를 계산할 수도 있다. 예를 들어, king과 man의 차이는 queen과 woman의 차이와 비슷하다. 즉, king과 man의 차이를 woman 벡터에 더하면 결과 벡터에 가장 가까운 단어는 queen이다. 마찬가지로 ramen과 Japan의 차이를 America에 더하면 burritos가 나온다. 신경망과 단어에 대한 분산 표현을 활용함으로써, AI가 언어의 단어 간의 의미적 유사성을 이해하게 되고, 이를 통해 인간 언어를 이해하고 생성할 수 있는 AI에 한 걸음 더 다가갈 수 있다.
신경망(Neural networks)
신경망은 입력을 받아서 네트워크에 전달하고 출력을 생성한다. 네트워크에 학습 데이터를 제공함으로써 입력을 출력으로 변환하는 작업을 점점 더 정확하게 수행할 수 있다. 일반적으로 기계 번역은 신경망을 사용한다. 실제로 단어를 번역할 때 문장이나 단락을 번역하려고 한다. 문장은 고정된 크기이므로 시퀀스를 크기가 고정되지 않은 다른 시퀀스로 변환하는 문제에 부딪힌다. AI 챗봇과 대화를 나눈 적이 있다면 단어 시퀀스를 이해하고 적절한 시퀀스를 출력으로 생성해야 한다.
순환 신경망은 신경망을 여러 번 다시 실행하여 모든 관련 정보를 보관하는 상태를 추적할 수 있다.
- 입력이 네트워크에 들어오면 숨겨진 상태가 생성된다.
- 두 번째 입력을 첫 번째 숨겨진 상태와 함께 인코더에 전달하면 새로운 숨겨진 상태가 생성된다. 이 프로세스는 종료 토큰이 전달될 때까지 반복된다.
- 그런 다음 디코딩 상태가 시작되어 마지막 단어와 다른 종료 토큰을 얻을 때까지 숨겨진 상태가 계속 생성된다.
그러나 몇 가지 문제가 발생한다.
- 인코더 단계에서는 입력 단계의 모든 정보를 하나의 최종 상태에 저장해야 하는 문제가 있다. 대규모 시퀀스의 경우 모든 정보를 단일 상태 값에 저장하는 것은 매우 어렵다. 모든 숨겨진 상태를 어떻게든 결합하면 유용할 것이다.
- 또 다른 문제는 입력 시퀀스의 일부 숨겨진 상태가 다른 상태보다 더 중요하다는 것이다. 어떤 상태(또는 단어)가 다른 상태보다 더 중요한지 알 수 있는 방법이 있을까?
Attention
Attention은 어떤 값이 다른 값보다 더 중요한지 결정하는 신경망의 능력을 의미한다. "매사추세츠의 수도는 무엇입니까?"라는 문장에서 attention을 통해 신경망은 출력 문장을 생성하는 각 단계에서 어떤 값에 주의를 기울일지 결정할 수 있다. 이러한 계산을 실행하면 신경망은 답의 최종 단어를 생성할 때 "자본"과 "매사추세츠"가 가장 주의해야 할 사항임을 보여준다. Attention 점수를 가져와서 네트워크에서 생성된 숨겨진 상태 값을 곱하고 합산함으로써 신경망은 디코더가 최종 단어를 계산하는 데 사용할 수 있는 최종 컨텍스트 벡터를 생성한다. 이와 같은 계산에서 발생하는 문제는 순환 신경망이 단어별로 순차적인 훈련이 필요하다는 것이다(=시간이 오래 걸린다). 대규모 언어 모델이 성장함에 따라 학습하는 데 시간이 점점 더 오래 걸린다. 점점 더 큰 데이터세트를 훈련해야 함에 따라 병렬성에 대한 욕구가 꾸준히 커졌다. 따라서 새로운 아키텍처가 도입되었다.
Transformer
Transformers는 각 입력 단어가 동시에 신경망을 통과하는 새로운 유형의 학습 아키텍처이다. 입력 단어는 신경망으로 들어가 인코딩된 표현으로 캡처된다. 모든 단어가 동시에 신경망에 입력되기 때문에 단어 순서가 쉽게 손실될 수 있다. 따라서 위치 인코딩(position encoding)이 입력에 추가된다. 따라서 신경망은 인코딩된 표현에서 단어와 단어의 위치를 모두 사용한다. 또한 입력되는 단어의 맥락을 정의하는 데 도움이 되는 셀프 어텐션(self-attention)단계가 추가되었다. 사실, 신경망은 종종 여러 셀프 어텐션 단계를 사용하여 맥락을 더 잘 이해할 수 있다. 이 프로세스는 시퀀스의 각 단어에 대해 여러 번 반복된다. 그 결과는 정보를 디코딩할 때 유용한 인코딩된 표현이다.
디코딩 단계에서는 이전 출력 단어와 위치 인코딩이 여러 self-attention 단계와 신경망에 제공된다. 또한 여러 주의 단계에 인코딩 프로세스의 인코딩된 표현이 공급되고 신경망에 제공된다. 그러므로 단어는 서로에게 주의를 기울일 수 있다. 또한, 병렬 처리가 가능하며 계산이 빠르고 정확하다.
우리는 광범위한 맥락에서 인공지능을 살펴보았다.
- 우리는 AI가 솔루션을 찾는 방법에서 검색 문제를 살펴보았다.
- 우리는 AI가 지식을 표현하고 지식을 생성하는 방법을 살펴보았다.
- 우리는 사물을 확실히 알지 못할 때의 불확실성을 살펴보았다.
- 우리는 최적화, 최대화 및 최소화 함수를 살펴보았다.
- 우리는 기계 학습, 훈련 데이터를 보고 패턴을 찾는 것을 살펴보았다.
- 우리는 신경망에 대해 배우고 신경망이 가중치를 사용하여 입력에서 출력으로 이동하는 방법을 배웠다.
- 오늘은 언어 자체와 컴퓨터가 우리 언어를 이해하도록 하는 방법을 살펴보았다.
우리는 이 과정의 피상적인 부분만 살펴봤다. 더 디테일한 내용은 인공지능프로그래밍에서 학습하도록 하겠다.
'인공지능 > 인공지능개론' 카테고리의 다른 글
| [AI] Neural Networks (6-2) (0) | 2024.06.28 |
|---|---|
| [AI] Neural Networks (6-1) (1) | 2024.06.28 |
| [AI] Learning (5-3) (0) | 2024.06.25 |
| [AI] Learning (5-2) (0) | 2024.06.24 |
| [AI] Uncertainty (3-3) (2) | 2024.06.24 |



