5장
1. 스레드가 시스템 호출 끝에 IO를 요청해 블록될 때: 블록상태 후 스케줄링
(CPU 활용률 향상)
2. 스레드가 자발적으로 CPU를 반활할때: 현재 스레드를 넣고 새로운 스레드 선택(CPU가 자발적 양보)
3. 스레드의 타임슬라이스가 소진되어 타이머 인터럽트 발생(균등한 CPU 분배)
4. 더 높은 순위의 스레드가 요청한 입출력 작업 완료, 인터럽트 발생: 현재스레드를 강제 중단시켜 높은 순위의 스레드를 깨워 스케줄링(우선순위를 지키기 위함)
기아: 스레드가 스케줄링에서 선택되지 못한 채 오랫동안 준비리스트에 있는 상황
에이징: 기아의 해결책, 머무른 시간비례 순위가 높아짐(짬순)
CPU 스케줄링 알고리즘들(그림 + 설명)
FCFS: 선착순 스케줄링
SJF: 실행시간 짧은순 스케줄링(현실성 사용되지 않음)
SRTF: 남은 시 간 짧은 순(현실에서는 거의 사용되지 않음)
RR:가능성 높음
Priority: 가능성 높음
6장
공유 데이터 접근 문제: 여러 스레드가 공유 변수에 접근할 때 공유 데이터가 훼손됨
해결: 스레드 동기화(접근 제어)
임계구역: 공유 데이터에 접근하는 코드들
상호 배제: 임계구역을 한 스레드만 베타적으로 독점하는 기술
lock 변수: 1이면 잠금, 0이면 열림

뮤텍스 락: 락변수 사용, 다른 스레드는 대기큐에서 대기, sleep-waiting기법
스핀 락: busy waitiong 기법, 대기하지 않고 락변수 계속 검사(CPU소모)

세마포: 멀티 스레드 사이 자원관리 기법
카운터 세마포: 여러개의 자원을 관리하는 세마포
이진 세마포: 한개의 자원을 관리하는 세마포(뮤텍스와 유사)
7장
교착상태: 자원을 소유한 스레드들 사이에 각스레드는 다른 스레드가 소유한 자원을 요청하여 무한 대기하는 현상
발생 원인:
- 자원: 교착상태는 멀티스레드가 자원을 동시에 사용할때 생김
- 자원과 스레드: 한 스레드가 여러 자원을 동시에 필요로할 때
- 자원과 운영체제: 한번에 하나의 자원만 할당하는 운영체제 정책 이유
- 자원 비선점: 할당된 자원은 강제로 뺏을 수 없음
발생 조건: 4가지 모두 발생해야함
- 상호 배제: 1자원 1스레드
- 소유+대기: 자원 소유 + 다른 자원 기다림
- 강제자원 반환 불가: 자원 강탈 불가
- 환형 대기(각스레드가 다른 스레드가 요청하는 자원을 들고 있는 인간지네느낌)
교착상태 해결방법
- 예방: 교착상태 발생 여지를 차단하여 예방(4가지 조건중 하나만 안되게 하기)
상호배제 제거: 2개이상의 스레드가 자원을 활용 / 소유 대기 안해도됨 / 강제 지원 가능: 강탈시키기 / 환형 대기 제거: 번호표 뽑기 - 회피: 자원 할당 시마다 미래의 교착 상태 가능성을 검사해 교착 상태가 발생하지 않을 것이라고 확신한 경우에만 지원할당(miss)
- 감지 및 복구: 교착상태를 감지하는 프로그램을 백그라운드에서 구동, 발견 후 교착상태 해제(자원소요 개많음)
자원 강제 선점: 강탈 가능 / 롤백: 세이브데이터 설정 / 스레드 강제 종료: kill 프로세스 - 무시: 교착상태는 없다고 단정, 아무런 대비책없음(되겠냐고~)
8장
메모리 계층 구조: CPU레지스터 > CPU 캐시 > 메인 메모리 > 보조기억장치
CPU 코어(레지스터<>L1,L2)>> L3 캐시 메모리 >> RAM >> 보조기억 장치(HDD등)
오른쪽으로 갈수록 용량 증가, 가격 저렴, 속도저하
메모리 계층 구조 중심: 메인 메모리(RAM)
메모리 계층화 성공이유: 참조의 지역성(코드나 데이터, 자원등이 짧은 시간 내에 다시 사용되는 특성 = 캐시를 채우는 시간보다 빠른 캐시를 사용하는게 이득)
메모리는 주소로만 접근 가능
물리 주소:
- 물리 메모리에 매겨진 주소, 하드웨어에 의해 고정된 메모리 주소
- 0에서 시작하는 연속적 주소 체계
- 메모리는 시스템 주소버스를 통해 주소의 신호를 받음
논리 주소:
- 프로세스 내에서 사용하는 주소, 코드나 변수등의 주소
- 0에서 시작해 연속된 주소 체계(상대 주소)
- 사용자나 프로세스는 결국 물리 주소를 알 수 없음
MMU: 논리 주소를 물리 주소로 바꾸는 하드웨어 장치
ASLR: 해커들이 메모리 공격에 대한 대비
- 주소 공간 랜덤 배치
- 프로세스의 주소 공간 내에서 스택이나 힙, 라이브러리 영역의 랜덤 배치
- 실행할 때마다 논리 주소 바뀜 >> 함수의 지역변수, 동적 할당 메모리의 논리 주소 변경
- 코드나 전역 변수가 적재되는 데이터 영역의 논리 주소는 바뀌지 않음

메모리 할당: 운영체제가 새 프로세스를 실행시키거나 실행중인 프로세스가 메모리를 필요로 할 때 물리 메모리 할당
프로세스의 실행은 할당된 물리 메모리에서 이루어짐.
연속 메모리 할당:
- 프로세스 별로 연속된 한 덩어리의 메모리 할당
- 고정 크기 할당: 메모리를 고정크기의 파티션으로 나누고 프로세스당 하나의 파티션 할당
메모리가 파티션들로 미리 나누어져있음 - 가변 크기 할당: 메모리를 가변 크기의 파티션으로 나누고 프로세스당 하나의 파티션 할당
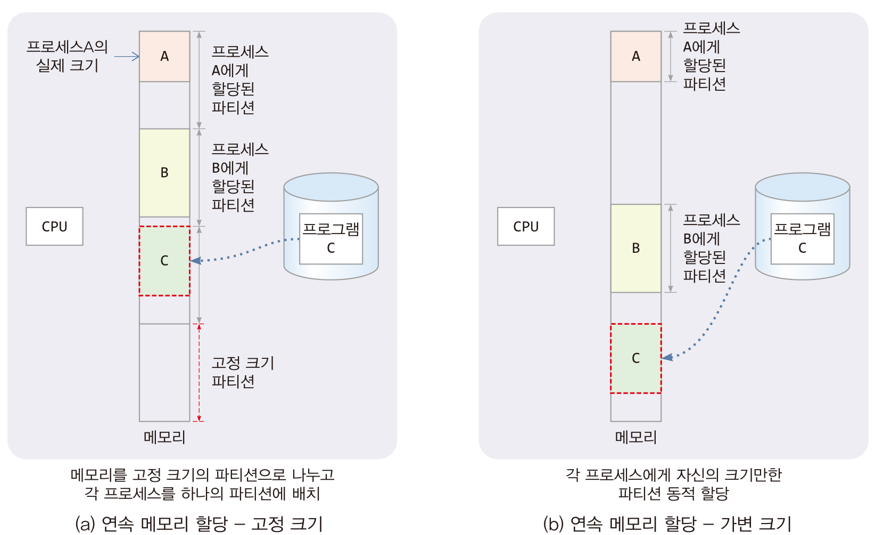
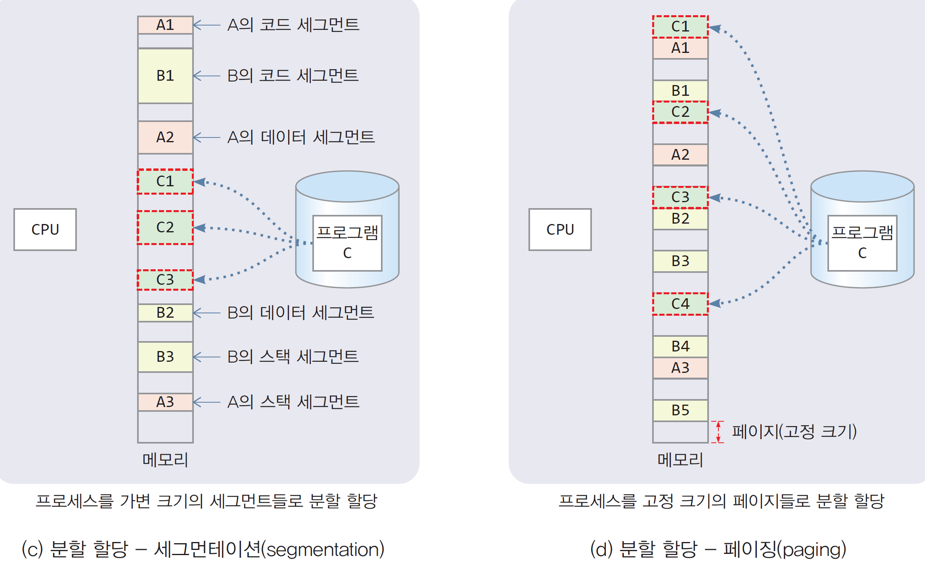
분할 메모리 할당:
- 프로세스에게 여러 덩어리의 메모리 할당
- 고정 크기 할당: 고정 크기의 덩어리 메모리를 분산 할당(페이징)
- 가변 크기 할당: 가변 크기의 덩어리 메모리를 분산 할당(세그먼테이션)
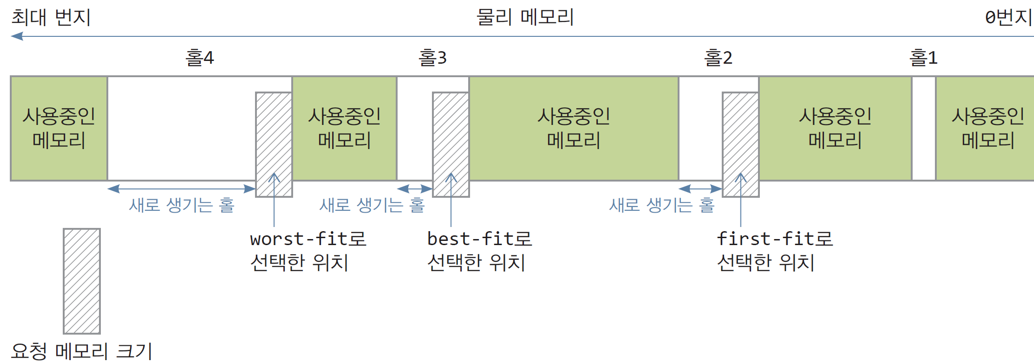
단편화: 프로세스에게 할당할 수 없는 조각 메모리(홀)들이 생기는 현상.
내부 단편화: 할당된 메모리 내부에 사용할 수 없는 홀이 생기는 현상.(파티션보다 작은 프로세스를 할당하는 경우 발생)
외부 단편화: 할당된 메모리들 사이에 사용할 수 없는 홀이 생기는 현상.(여러개의 작은 홀 생성, 홀이 프로세스크기보다 작으면 할당 불가)
9장
페이징:
프로세스의 논리 주소공간을 동일한 크기의 페이지로 나눔
물리 메모리를 페이지 크기로 나누어 프레임을 만들고
페이지를 프레임에 할당시키는 방식
페이지 크기: 주로 4KB
페이지 테이블: 각 페이지에 대한 페이지 번호와 프레임 번호를 1대1로 저장하는 테이블
페이징 기법
- 프로세스의 주소 공간과 물리 메모리를 페이지 단위로 분할하고, 프로세스의 각 페이지를 물리 메모리의 프레임에 분산 할당하여 관리하는 기법
- 프로세스의 주소 공간: 0에서 시작하여 연속적인 주소 공간
- 프로세스마다 페이지 테이블 있음
- 논리 주소의 물리 주소 변환 : MMU
- 물리 메모리의 빈 프레임 리스트 관리 필요(프레임 할당 알고리즘 : 빈 프레임 중에서 선택하는 알고리즘 필요)
- 내부 단편화 발생
- 세그먼테이션보다 우수
페이지와 페이지 테이블
예시를 들어 알아보자.
프로세스 주소 공간: 4GB
페이지 크기 4KB
사례 프로세스:
페이지 테이블 문제점:
1. 메모리에 접근 시 2번이나 접근함 = 1번에 메모리 엑세스를 위한 2번의 물리 메모리 액세스
페이지 테이블 항목 읽기: 메모리에서 페이지 테이블 항목을 읽어 물리 주소를 가져온다.
데이터 접근: 가져온 물리 주소를 이용해 실제 데이터를 읽는다.
결과: 이 과정 때문에 실행 속도가 느려진다. 한 번의 작업을 위해 두 번 메모리에 접근하기 때문이다.
해결책: TLB(변환 색인 버퍼)
TLB는 페이지 테이블 항목을 저장하는 캐시 역할을 한다. 이를 통해 페이지 테이블을 매번 읽을 필요가 없어지고, 속도가 빨라진다.
TLB를 이용한 물리 메모리 액세스 해결:
논리 주소를 물리 주소로 바꾸는 과정에서 페이지 테이블을 읽어오는 시간을 없애거나 줄이는 기법
TLB(Translation Look-aside Buffer) 사용
- 주소 변환 캐시(address translation cache)로 불림
- 최근에 접근한 ‘페이지 번호와 프레임 번호’의 쌍을 항목으로 저장하는 캐시 메모리
- 현대 컴퓨터에서는 MMU 내에 존재
TLB 캐시의 구조와 특징
- [페이지 번호 p, 프레임 번호 f]를 항목으로 저장
- 페이지 번호로 전체 캐시를 동시에 고속 검색, 프레임 번호 출력
- content-addressable memory, associative memory라고 불림
- 고가, 크기 작음(64~1024개의 항목 정도 저장)

TLB와 참조의 지역성
- TLB는 참조의 지역성으로 인해 효과적인 전략임
- TLB를 사용하면, 순차 메모리 액세스 시에 실행 속도 빠름
TLB 히트가 계속됨(메모리의 페이지 테이블 액세스할 필요 없음)
TLB를 사용하면, 랜덤 메모리 액세스나 반복이 없는 경우 실행 속도 느림 - TLB 미스 자주 발생
- TLB의 잦은 항목 교체(TLB 항목 수가 제한되기 때문)
TLB 성능
- TLB 히트율 높이기 >> TLB 항목 늘이기(비용과 trade-off)
- 페이지 크기
페이지가 클수록 TLB 히트 증가 >> 실행 성능 향상
페이지가 클수록 내부 단편화 증가 >> 메모리 낭비
페이지가 크면 장단점이 동시에 존재하므로 선택의 문제
현대에서 페이지가 커지는 추세 : 디스크 입출력의 성능 향상을 위해
TLB reach
TLB 도달 범위
- TLB가 채워졌을 때, 미스없이 작동하는 메모리 액세스 범위
- TLB 항목 수 * 페이지 크기
페이지 테이블 메모리 낭비 문제 해결
역 페이지 테이블:
- 물리 메모리 전체 프레임에 대해, 각 프레임이 어떤 프로세스의 어떤 페이지에 할당되었는지를 나타내는 테이블
- 시스템에 1개의 역 페이지 테이블 둠(역 페이지 테이블 항목의 수 = 물리 메모리의 프레임 개수)
- 역 페이지 테이블 항목
[프로세스번호(pid), 페이지 번호(p)] - 역 페이지 테이블의 인덱스
프레임 번호 - 역 페이지 테이블을 사용할 때 논리 주소 형식
[프로세스번호, 페이지 번호, 옵셋] - 역 페이지 테이블을 사용한 주소 변환
논리 주소에서 (프로세스번호, 페이지 번호)로 역 페이지 테이블 검색
일치하는 항목을 발견하면 항목 번호가 바로 프레임 번호임
프레임 번호와 옵셋을 연결하면 물리 주소
역 페이지 테이블 크기
- 역 페이지 테이블 항목 : 프로세스 번호와 페이지 번호로 구성
프로세스 번호와 페이지 번호가 각각 4바이트라면, 항목 크기는 8 바이트 - 역 페이지 테이블의 항목 수 = 물리 메모리 크기/프레임 크기
예) 물리 메모리가 4GB, 프레임 크기 4KB이면 역 페이지 테이블 항목 수 = 4GB/4KB = 2^20개 = 약 100만개 - 역 페이지 테이블 크기는 컴퓨터에 설치된 물리 메모리 크기에 따라 달라짐
예) 물리 메모리가 4GB, 프레임 크기가 4KB, 한 항목 크기가 8바이트라면 역 페이지 테이블의 크기 = 2^20개 항목 x 8바이트 = 8MB
기존 페이지 테이블과 비교
예) 10개의 프로세스가 실행 중일 때(물리 메모리가 4GB인 경우)
기존 페이지 테이블 = 4MBx10개 = 40MB 크기
역 페이지 테이블 = 8MB(기존의 1/5 수준)
멀티 레벨 페이지 테이블
프로세스가 현재 사용 중인 페이지들에 대해서만 페이지 테이블을 만드는 방식
기존 페이지 테이블의 낭비를 줄임
페이지 테이블을 수십~수백 개의 작은 페이지 테이블로 나누고 이들을 여러 레벨(level)로 구성
오늘날 대부분 운영체제에서 사용되고 있음
2-레벨로 멀티레벨 페이지 테이블을 구성하는 경우
논리 주소 구성
[ 페이지 디렉터리 인덱스, 페이지 테이블 인덱스, 옵셋 ]
페이지 크기 4KB
논리 주소의 하위 12비트 : 페이지 내 옵셋 주소
논리 주소의 상위 20비트 : 페이지 디렉터리 인덱스와 페이지 테이블 인덱스

2-레벨 페이지 테이블의 최대 메모리 소모량
페이지 디렉터리 1개 + 최대 1024개의 페이지 테이블
= 4KB + 1024*4KB = 4KB + 4MB
하지만, 대부분의 경우, 프로세스는 그리 크지 않음
사례 1 – 프로세스가 1000개의 페이지로 구성되는 경우(4MB의 프로세스)
1000개의 페이지는 1개(4KB)의 페이지 테이블에 의해 매핑 가능
메모리 소모량
1개의 페이지 디렉터리와 1개의 페이지 테이블
= 4KB + 4KB = 8KB
사례 2 – 프로세스가 400MB 크기인 경우
프로세스의 페이지 개수 = 400MB/4KB = 100×1024 개
100개의 페이지 테이블 필요
메모리 소모량
1개의 페이지 디렉터리와 100개의 페이지 테이블
= 4KB + 100×4KB = 404KB
결론
기존 페이지 테이블의 경우, 프로세스 크기에 관계없이 프로세스 당 4MB가 소모
2-레벨 페이지 테이블의 경우, 페이지 테이블로 인한 메모리 소모를 확연히 줄일 수 있다