P2P applications
순수 P2P 구조
항상 서버가 열려 있지 않다.
임의의 엔드 시스템이 직접 통신한다.
Peer가 간헐적으로 연결되고 IP 주소가 변경된다.
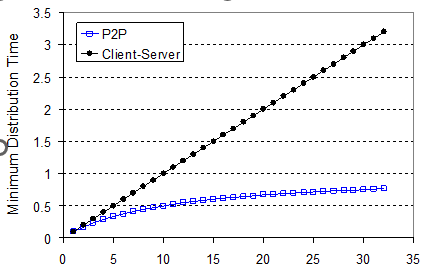
서버-클라이언트 VS P2P 구조 응답시간
Client upload rate = u, F/u = 1 hour, us = 10u, dmin ≥ us
파일 분산: Bit Torrent
한 피어가 토렌트에 가입할 때 트랙커에 자신을 등록하고 주기적으로 자신이 아직 토렌트에 있음을 알린다.
인덱스 서버는 컨텐츠에 대한 카탈로그를 가지고 있음
- torrent: 피어들의 그룹을 청크 파일로 변환시킴
- tracker: 토렌트에 참여하는 피어를 추적함. / 트래커는 인덱스서버가 아닌 그저 피어들끼리 통신하게 참여하는 것이다.
- 파일을 256KB 청크로 분할
- 토렌트에 가입하는 피어는 청크가 없지만 시간이 지나면서 청크를 축적
- 트래커에 등록하여 피어 목록을 얻고, 피어의 하위 집합(neighbor)과 연결
- 피어가 전체 파일 확보시 탈퇴하거나 남아있을 수 있다.
청크 요청: 피어는 가장 드문 청크를 먼저 요청
- 언제든지 피어마다 파일 청크의 하위 집합이 다르다.
1. 주기적으로 피어(앨리스)가 각 이웃에게 가지고 있는 청크 목록을 요청한다.
2. 앨리스는 가지고 있지 않은 청크 중에서 가장 희귀한 청크를 먼저 요청한다.
3. 그 결과 토렌트에 있는 각 청크의 사본 수가 같아진다.
Rarest missing chunks first: 가장 드문 청크(즉, 이웃들 중에 가장 적은 반복 복사본을 가진 청크)를 먼저 요구함으로써,
이러한 방법으로 가장 드문 청크들은 더 빨리 재분배될 수 있어서 토렌트에 각 청그의 복사본 수가
(대략적으로) 동일하게 할 수 있다.
청크 전송(티키타카): 가장 높은 속도로 청크를 제공하는 네 이웃에게 우선순위 부여
1. 앨리스는 현재 가장 높은 비율로 청크를 먹이고 있는 이웃 4곳에 우선 순위를 부여(청크 전송)한다.
2. 10초마다 상위 4개 evaluate 다시보기
3. 30초마다: 다른 피어를 무작위로 선택하고 청크 전송을 시작한다.
4. 새로 선택된 피어가 상위 4위에 합류할 수 있다
“optimistically unchoke”: 낙관적으로 활성화됨.
Tit-for-tat: 경기자는 처음에는 협력하고, 그 이후에는 상대의 바로 전 전략에 반응한다.
만약 상대가 이전에 협력을 했다면, 경기자는 협력하고, 만약 배반했다면, 경기자는 배반할 것이다.
P2P: 정보 탐색
파일 공유: 색인은 각 파일의 복사본 및 그 복사본을 가진 피어의 IP 주소 매핑 레코드 유지
파일 공유(예: 전자 모듈)
인덱스는 피어가 공유하는 파일의 위치를 동적으로 추적합니다.
피어는 인덱스에 자신이 가진 것을 알려줘야 합니다.
파일을 찾을 수 있는 위치를 결정하는 피어 검색 인덱스
인스턴트 메시징, 인터넷 전화: 색인은 사용자 이름 및 현재 로그인한 컴퓨터의 IP 주소 매핑 레코드 유지
인스턴트 메시징:
인덱스는 사용자 이름을 위치에 매핑합니다.
사용자가 IM 애플리케이션을 시작할 때는 해당 위치를 인덱스에 알려야 합니다.
피어 검색 인덱스를 사용하여 사용자의 IP 주소를 확인합니다.
1세대 P2P: 중앙화된 인덱스
피어가 연결되면 중앙 서버에 IP 주소와 컨텐트를 알림
문제점: 단일 장애 지점, 병목 현상, 저작권 침해
2세대 P2P: 쿼리 플러딩
완전히 분산된 구조, 중앙 서버 없음, 각 피어는 자신이 공유하는 파일을 인덱싱함.
오버레이 네트워크: 그래프를 사용함
쿼리 메시지를 기존 TCP 연결을 통해 전송
피어가 쿼리 메시지 전달
쿼리 히트 메시지를 역뱡향 경로로 전송
참여 노드에 의해 생성된 가상(또는 논리적) 네트워크;
예를 들어 클라우드 컴퓨팅, P2P 네트워크, 클라이언트-서버 애플리케이션과 같은 분산형 시스템
노드가 인터넷 위에서 실행되기 때문에 오버레이 네트워크입니다.
확장성 결여: 피어가 질의를 초기화할 때마다 그 질의는 전체 오버레이 네트워크로 전달되어 상당한 양의 트래픽 생성
제한 범위 질의 플러딩 (limited-scope query flooding)은 초기 질의 메시지를 보낼 때 피어 수 필드(peer count field)에 제한 값 (예, 7)을 설정하여, 수신한 피어가 질의를 전달하기 전에 피어수 필드 값을 줄이고, 피어 수 필드 값이 ‘0’인 질의를 받으면 질의 전달을 멈춘다. 상당한 트랙픽 발생을 줄일 수 있으나, not guarantee that data will be found!
3세대 P2P: 계층적 오버레이
중앙 집중식 인덱스와 쿼리 플러딩 접근 방식 간의 좋은 기능 조합.
각 피어는 슈퍼 노드이거나 어렸을 때 슈퍼 노드에 할당된다.
- 피어와 해당 슈퍼 노드 간의 TCP 연결.
- 일부 슈퍼 노드 쌍 간의 TCP 연결.
슈퍼 노드는 하위 노드의 콘텐츠를 추적한다.
분산 해시 테이블(DHT) 사용
DHT: distributed hash table
보다 구조화된 키 기반 라우팅
DHT = 간단한 정보 인덱싱(즉, 간단한 데이터베이스) 및 쿼리를 지원하는 수많은 피어에 분산된 P2P 데이터베이스
데이터베이스에는 (키, 값) 쌍이 있다;
- 키: 콘텐츠 유형, 값: IP 주소
1. 피어가 (키, 값) 쌍 삽입
2. 피어가 키로 DB를 요청
-DB는 키와 일치하는 값을 반환
DHT의 동작 방식
DHT에서는 다음과 같은 전제 조건을 가지고 서비스가 제공된다.
1) DHT에 참가하는 모든 호스트들의 IP주소를 해시함수에 넣고 돌리면 index 값이 나온다. 이를 index1 이라 하자.
2) 공유할 파일을 해시함수에 넣고 돌리면 index 값이 나온다. 이를 index2 라 하자.
3) index1과 index2값이 같으면, index2에 해당하는 파일의 위치를 index1에 해당하는 호스트가 가지고 있는다.
4) 만약 index2에 해당하는 index1이 없으면, index2 보다 크면서 가장 가까이 있는 index1이 index2에 해당하는 파일의 위치를 가지고 있는다.
5) 각 호스트들은 자신과 인접한 호스트의 IP 주소를 알고 있다.
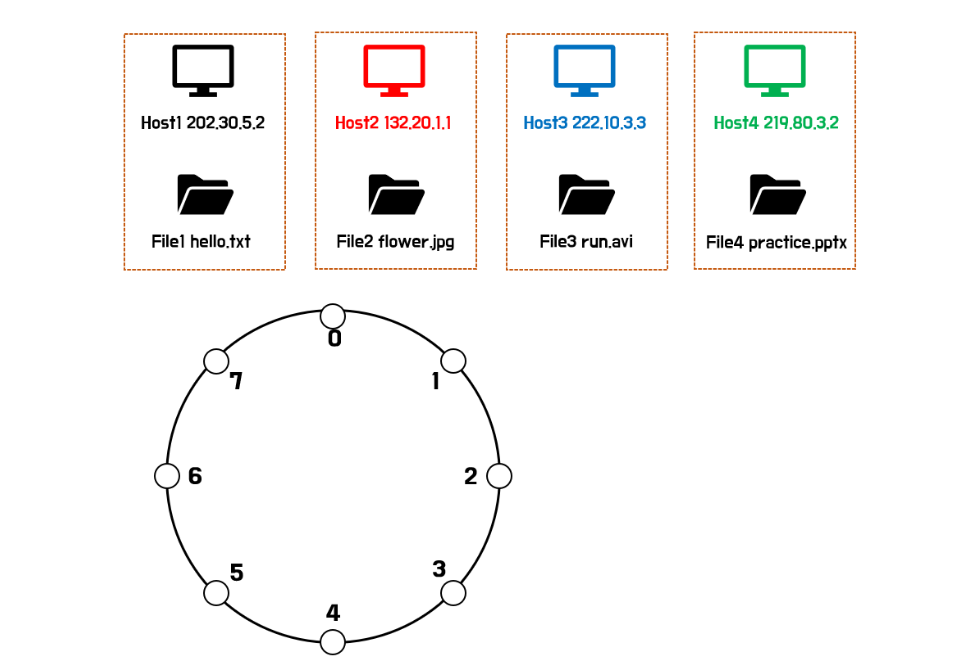
우선 위의 그림에서 노드의 개수를 보면 알 수 있듯이, 해시 테이블의 index 범위는 [0,7]이다.
그림의 위쪽에 호스트가 총 4개가 있고, 아래쪽에 공유할 파일도 총 4개가 있다.
각각의 호스트들은 파일을 하나씩 들고 있다. 예를 들어 Host1은 'hello.txt'파일을 가지고 있고, Host4는 'practice.pptx' 파일을 가지고 있다.
이제 앞서 살펴보았던 index1를 구해야 한다. index1은 각 호스트의 IP주소에 해시함수를 적용해 구할 수 있다.
아래 그림처럼 각각의 호스트들이 index를 할당받았다고 가정해보자.
그렇다면 이제 각각의 호스트들은 자신과 인접한 호스트의 IP주소를 알고 있다.

이제 index2를 구해보자. index2는 파일을 해시함수에 적용해 구할 수 있다.

위의 그림에서 해시함수를 통해 index2를 구했다. 'hello.txt'의 해시함수 결과는 4 이므로 4번 index를 가진 Host3이 'hello.txt'의 위치를 알고 있으면 된다.
'run.avi'의 해시함수 결과는 6인데, 6번 index를 가진 호스트는 없다. 따라서 6번보다 크면서 가장 가까운 7번 index를 가진 Host4가 'run.avi'의 위치를 알고 있으면 된다.
'flower.jpg'의 해시함수 결과는 1인데, 1번 index를 가진 호스트는 없다. 따라서 1번보다 크면서 가장 가까운 2번 index를 가진 Host1이 'flower.jpg'의 위치를 알고 있으면 된다.
만약 Host1이 'practice.pptx'를 다운받고 싶어한다고 해보자. 우선 해당 파일을 가지고 있는 호스트를 찾아야 할 것이다. Host1은 자신의 다음 호스트인 index 4번의 Host3에게 물어본다.
Host3은 'hello.txt'의 위치만 알고있으므로 자신의 다음 호스트인 index 5번의 Host2에게 물어본다.
Host2는 'practice.pptx'의 위치를 알고 있으므로 질문을 한 Host1에게 파일의 위치를 알려주게 된다.
이 과정을 그림으로 나타내면 아래와 같다.

https://velog.io/@tg-96/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%ACDHTDistributed-Hash-Table
[네트워크]DHT(Distributed Hash Table)
✍️DHT란?파일을 공유하는 방법 중 하나이다.P2P모델은 중앙서버가 없지만 속도가 느리다는 단점이 있고, client-server architecture은 중앙서버가 있지만, 서버 부담이 크다는 단점이 있다.위 두 모델
velog.io
https://seungyooon.tistory.com/120
[컴퓨터 네트워크] Kademlia DHT 카뎀리아 분산해시테이블 알아보기
Kademlia의 개념 분산 P2P(peer-to-peer) 컴퓨터 네트워크를 위한 분산해시테이블(Distributed Hash Table DHT) UDP를 사용해서 노드간 소통 ** UDP : User Datagram Protocol / 데이터를 데이터그램/독립적인 패킷 단위로
seungyooon.tistory.com
DASH:
가용 대역폭이 충분할 때는 높은 비트율의 비디오 버전을 요청하며, 가용 대역폭이 적을 때는 낮은 비트율의 비디오 버전을 요청한다.
즉, 클라이언트는 자신의 상황에 알맞은 비디오 버전을 요청한다.
각 비디오 버전은 HTTP 서버에 서로 다른 URL을 가지고 저장된다.
HTTP 서버는 비트율에 따른 각 버전의 URL을 제공하는 매니페스트(manifest) 파일을 갖고 있다.
클라이언트는 이 매니페스트 파일을 제공받고,
이에 따라 매번 원하는 버전의 비디오 조각 단위를 선택하여 HTTP GET 요청 메시지에 URL과 byte-range를 지정하여 요청한다.
궁극적으로 DASH는 클라이언트가 서로 다른 품질 수준을 자유롭게 변화시킬 수 있도록 허용한다.
CDN:
DN은 다수의 지점에 분산된 서버들을 운영하며, 비디오 및 다른 형태의 웹 콘텐츠 데이터의 복사본을 이러한 분산 서버에 저장한다.
사용자는 최적의 사용자 경험을 제공받을 수 있는 지점의 CDN 서버로 연결된다.
CDN은 구글처럼 사설 CDN일 수도 있으며, 제 3자가 운영하는 CDN을 통해 서비스될 수도 있다.
두 개의 철학 중 하나를 채용한다.
- Enter Deep
- Bring Home
push CDN servers deep into many access networks
Akamai에 의해 주창된 것으로서 서버 클러스터를 세계 곳곳의 접속 네트워크에 구축함으로써 ISP의 접속 네트워크로 깊숙이 들어가는 것이다.
즉, 최대한 서버를 사용자 근처에 위치시켜 링크 및 라우터를 거치는 횟수를 줄여 지연시간 및 처리율을 개선하는 것이다.
smaller number (10’s) of larger clusters in POPs near (but not within) access networks
Limelight와 다른 회사들에 의해 적용된 것으로, 좀 더 적은 수의 핵심 지점에 큰 규모의 서버 클러스터를 구축하여 ISP를 Home으로 가져오는 개념이다.
접속 ISP에 연결하는 대신, 일반적으로 CDN들은 그들의 클러스터를 인터넷 교환 지점(IXP)에 배치한다.
이에 따라 Enter Deep보다 처리율(throughput)은 더 낮고 delay가 더 걸릴 수 있지만, 회사의 입장에서는 유지 보수하기에 편하며, 비용이 적게 든다.
CDN은 콘텐츠의 복사본을 이들 클러스터에 저장하는데 모든 복사본을 유지하지는 않는다.
어떤 비디오는 인기가 거의 없거나 특정 국가에서만 인기가 있을 수 있기 때문이다.
실제로 CDN은 클러스터에 대해 사용자의 요청이 오면 중앙 서버나 다른 클러스터로부터 전송받아 사용자에게 서비스하는 동시에 복사본을 만들어 저장하는 pull 방식을 이용한다.
저장 공간이 가득 차게 되면 자주 사용되지 않는 비디오 데이터는 삭제된다.
- 사용자가 URL을 지정하여 비디오를 요청한다.
- CDN은 그 요청을 가로채 클라이언트에게 가장 적당한 CDN 클러스터를 선택한다.
- 클라이언트의 요청을 해당 클러스터의 서버로 연결한다.
요청을 가로챌 때 CDN은 DNS를 활용한다. 이를 DNS redirection이라고 한다.

- 사용자가 URL을 입력한다.
- 사용자의 호스트는 URL의 host name에 대한 질의를 로컬 DNS로 보낸다.
- 로컬 DNS는 host name의 책임 DNS 서버로 질의를 전달한다.
책임 DNS 서버는 해당 질의를 CDN 서버로 연결하기 위해 CDN 서버의 책임 DNS 서버의 IP를 전달한다. - 로컬 DNS는 CDN 서버의 책임 DNS로 질의를 보내고, CDN 콘텐츠 서버의 IP 주소를 로컬 DNS 서버로 응답한다.
이때 클라이언트가 콘텐츠를 전송받게 될 서버가 결정된다. - 로컬 DNS 서버는 사용자 호스트에게 CDN 서버의 IP 주소를 알려준다.
- 클라이언트는 호스트가 알게된 IP 주소로 HTTP 혹은 DASH 프로토콜을 통해 비디오를 받아온다.
NAT
생긴 이유: 로컬 네트워크는 외부 세계에 관한 한 단 하나의 IP 주소만 사용합니다:
- IP 주소 부족
- 로컬 넷 내부의 디바이스는 명시적으로 주소 지정이 불가능하며 외부에서 볼 수 있다(보안 플러스)
- 외부에 알리지 않고 로컬 네트워크에 있는 장치의 주소를 변경할 수 있다
- 로컬 네트워크의 장치 주소를 변경하지 않고도 ISP를 변경할 수 있다
슈퍼노드, 릴레이 노드:
솔루션: SN & 릴레이
1. 앨리스와 밥의 SN을 사용하여 릴레이가 선택된다.
2. 각 피어는 릴레이를 통해 세션을 시작한다.
3. 이제 피어는 릴레이를 통해 NAT을 통해 커뮤니케이션할 수 있다.

Alice는 로그인하면 NAT에 가입하지 않은 슈퍼 피어가 할당된다.
앨리스는 슈퍼 피어에게 세션을 시작하게 할 수 있다. 밥이 로그인하면 밥도 마찬가지임.
이제 앨리스는 밥에게 전화하고 싶을 때 슈퍼 피어에게 알렸고, 피어는 밥에게 다음과 같이 알린다:
1. 밥의 슈퍼 피어는 밥에게 앨리스의 전화가 걸려왔다고 알립니다.
2. 밥이 통화를 수락하면 두 슈퍼 피어가 세 번째 슈퍼 피어인 릴레이 노드를 선택한다.
3. 앨리스와 밥 사이에 데이터를 전달하는 일을 맡게 됩니다.
4. 그런 다음 앨리스와 밥의 슈퍼 피어들은 각각 앨리스와 밥에게 릴레이 세션을 시작하도록 지시한다.
5. Alice는 Alice-to-relay 연결을 통해 음성 패킷을 릴레이 서버로 전송한다.
6. 릴레이는 릴레이와 밥 연결을 통해 이러한 패킷을 전달한다; Bob의 패킷
7. 앨리스는 이 두 개의 릴레이 연결을 거꾸로 통과한다.
Bob과 Alice는 세션을 수락할 수 없음에도 불구하고 온디맨드 엔드투엔드 연결을 제공합니다


